Hmm, I know what you mean Nintendo Maniac, but unfortunately I do not think that more developer attention would be able to massively improve the performance of APUs, as there are a few fundamental problems with the promised performance of these HSA systems:
1) Consumer interest seems to be driving a new race to the bottom, where companies focus on systematically developing
less and less powerful (euphemistically referred to as "efficient") processors every couple of generations.
A lot of people seem to believe that it is a lack of competition, or even insurmountable technological problems, that
confines us to single-digit percentage point improvements in real-world CPU performance (when both are overclocked
as far as stability allows, the difference between a Sandy-Bridge based CPU and all of the following architectures,
including the latest Broadwell chips, is practically nonexistent), together with a greatly slowed rate of GPU performance
increases as well.
However; the truth is that the IC fabrication plants are optimized to produce "low power" transistors. Even their "High-
Power" processes were engineered with 10-30W processors in mind. With almost every reviewer also shouting the
praises of power being more important than performance, no company is going to be able to convince its directors to
take the risk of investing billions of dollars into developing a true high-performance manufacturing node.
To illustrate the crux of the matter, please have a look at the following graph (unfortunately it is already 6-years out
of date, but the general trends are still valid. Also, please excuse the size of the image, none of the BBCode resize tags
seems to work...):
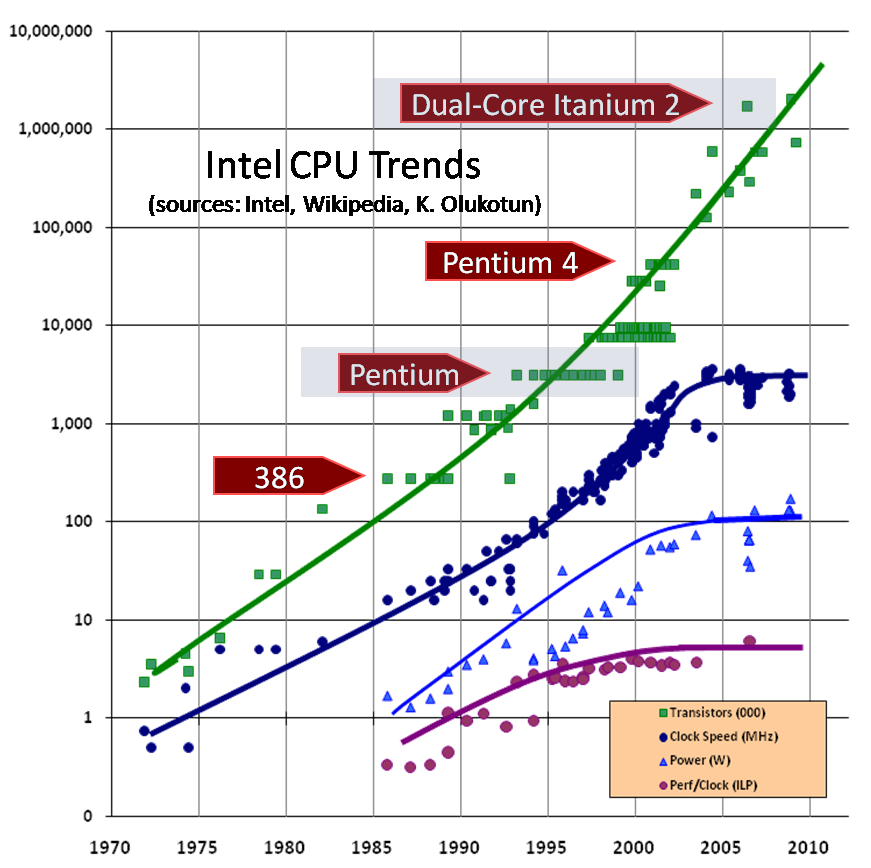
This image was taken from The Free Lunch is Over, where the basics of the problem is explained in much more detail.
Alright, so what does all of this have to do with HSA development? Well, forcing the GPU to occupy the same space and
power delivery circuitry as the CPU only serves to exacerbate the problem. This arrangement might not have been so
bad, if we already had enough performance to process high-resolution and high-framerate video. It might even have
brought some performance advantages (due to a, theoretically, much faster interconnect fabric).
As it stands, however, the PCI-Express bus does not really bottleneck the performance of a well-written algorithm (you
can prepare each frame on the CPU and only send it once over the bus, having the GPU then display it as soon as it
has finished applying the required calculations. As an added bonus, only the source frames would need to be
transferred, all interpolated frames can simply be drawn straight by the GPU.
It seems like the only real "workaround" is to make use of multiple "add-in" cards to bring the system's power up to
something reasonable.
2) Even with the extra theoretical performance that an integrated GPU would bring, almost all "real-time" programs rely
on a single logical thread to control the program's flow and to dispatch, collect and organize the flow of data and
commands. Of special importance, is this "master" process' ability to quickly (with the lowest possible latency) resolve
race conditions and deadlocks that arise due to the asynchronous nature of multi-threaded processing (see also
Amdahl's Law).
Obviously, a given processor's instruction latency is directly dependent on its instruction throughput per clock cycle
(it's IPC) times its clock rate which, as can be seen in the above image, have both basically stagnated together with
the processor's power budget.
These are the main reasons why I am so excited about the implementation of new SIMD instructions, as they are able to massively increase (double in the case of AVX2) the amount of data that can be operated on in parallel by a single thread, without either the clock speed or the IPC having to be increased.
I do apologize for the length of this post (and for my English), but some of the issues involved are somewhat complicated.
Hopefully I (or rather the linked articles  ) have adequately explained how "making increased use of the increased parallel processing power of HSA" by breaking up traditionally serial logic pathways and distributing them over the integrated GPU, can actually slow down the program as a whole.
) have adequately explained how "making increased use of the increased parallel processing power of HSA" by breaking up traditionally serial logic pathways and distributing them over the integrated GPU, can actually slow down the program as a whole.
As for your comment about current hardware already being able to "max out" SVP for 1080P videos; I totally agree.
(As an interesting aside, for some types of content, having a larger "motion vectors grid" setting results in less artifacts and better detail preservation. So, "maxed out" settings do not always have to be the most computationally intensive either  ).
).
Anyway, when MVTools was written, block-matching was the only remotely practical way to interpolate motion in real time on the hardware of the day. While this is very fast and works great for 2D planar motion (such as the sideways panning of a camera) it does not take into account factors such as depth or occlusion (such as when a moving object or character is partially obstructed by a channel logo or a picket fence) or even of the connectedness of solid lines (a straight edge should remain straight, even when in motion).
And while such 2D planar motion does make up a very large share of the most obnoxious motion artifacts of low-framerate video, I do hope that we will one day have some form of motion interpolation software that is based upon continuous partial derivatives and accurate phase correlation; if not in this decade then hopefully at least during the early 2020s, because I am sure we at least have enough computational power to pull it off.